One of the most interesting deep learning projects in computer science today is the development and use in multiple forms of Generative Adversarial Networks (GAN). In this article, we give you an overview of how it works and what it can be used for.
The definition of GAN
The idea of a GAN was born thanks to a group of researchers trying to find a solution on how to make machine learning models learn better and faster. Among them was Ian Goodfellow who wrote the first article to present and explain this new model in 20141.
As it is written in its name a GAN is a generative model based on deep learning model architecture. Unlike a discriminative model, which associates data according to the input and output, the generative model has the capacity to generate new data close to the input data. For example, if we give him a picture of a cat and explain that it’s a cat it is supposed to be able to generate a picture of a cat close to reality so that a discriminative model wouldn’t be able to tell if it’s fake. This is why this kind of model is also defined as an unsupervised model since it’s supposed to discover and learn by itself the regularities and patterns of the dataset input and generate a new output close to it.
In this way, the GAN is considered as a solution to train generative models. It is composed of two neural networks : a generator and a discriminator. The generator is the network in charge of generating new data. It could be seen as the artist learning how to reproduce the art of well-known artists. The discriminator is the network in charge of distinguishing between real and fake data. It is as an art critic trying to differentiate art pieces between those of true artists and those of contrafactors. These two neural networks are competing against each other until the discriminator can’t recognize the real ones from the fake ones. Their learning pattern is close to a zero sum game where the improvement of one comes at the loss of the other. Here, the more the generator becomes efficient the more the discriminator’s capacity is reduced and frozen with a 50% percent chance of differentiating the fake from the real ones.
The model architecture
The model architecture of GAN is based on a two steps learning process that isn’t running at the same time to prevent any form of confusion for each neural network. On one side there is the discriminator. To make it run it needs an input of real data and an input of fake data generated by the generator. During the training phase those images will appear randomly and the discriminator will learn how to differentiate them. At the beginning the exercise is simple to solve for it because the generator isn’t able to create data close to the real one.
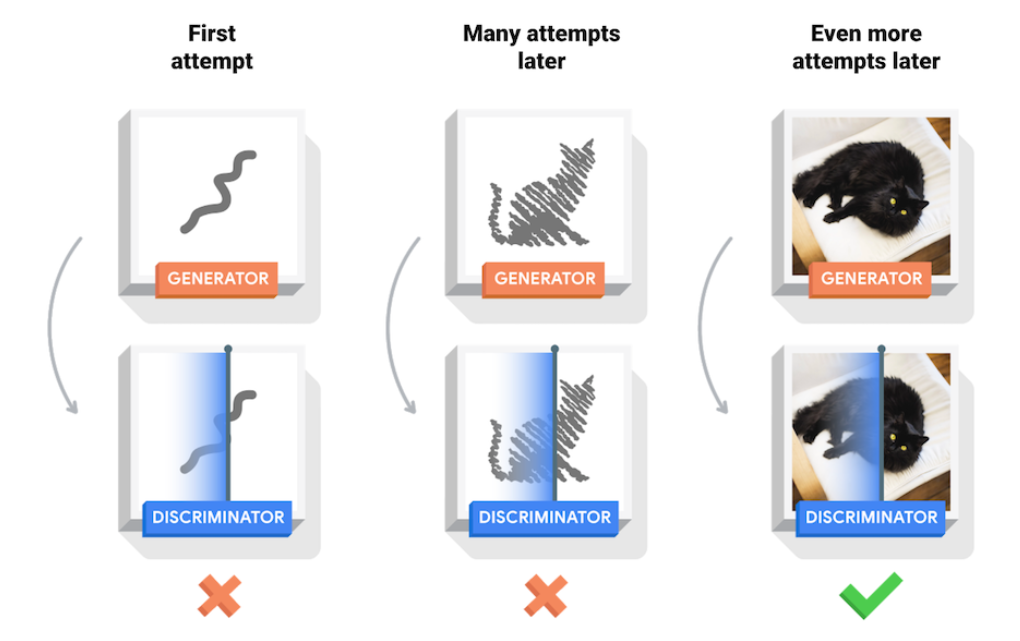 Figure 1: Learning step of GAN2
Figure 1: Learning step of GAN2
Nevertheless, as the generator is training, the task becomes more and more difficult for the discriminator. Everytime it doesn’t succeed in differentiate from real to fake ones, it has to upload his weight thanks to backpropagation
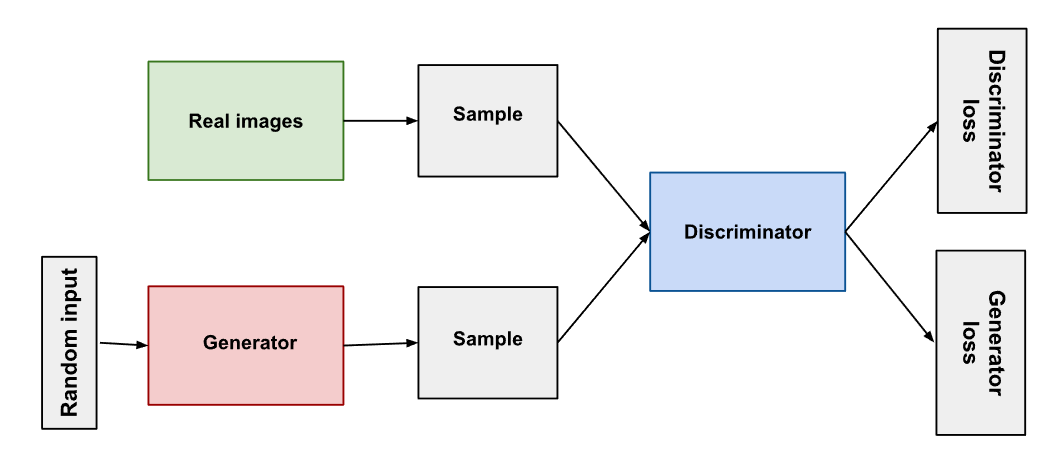 Figure 2: Model architecture of GAN3
Figure 2: Model architecture of GAN3
On the other side, there is the generator’s network. First we give him some random input, usually noise because it’s the easiest material to generate anything out of it. However, it is not the case for every GAN, some of them are using a specific input to generate a precise output. After creating the image, it sends it to the discriminator which will do his part. If the generator can’t fool the discriminator then, the backpropagation will pass through the discriminator to send the information to the generator and this is where the two neural networks are connected. This is why the weights of the discriminator are changed only when the generator isn’t working, otherwise it wouldn’t be able to send any data to the discriminator. The progress of the model can be checked with the loss functions. Usually, a GAN has two loss functions, one for each neural network and they measure the distance between probability distributions.
Uses of GAN
Today, there are a lot of ways to use GAN in multiple fields because it is able to generate sounds, videos, images and more. Actually, they are mainly used to generate images or pictures as the model “this person doesn’t not exist” which is able to generate faces of people who don’t exist. The same technique is used for deep fakes except that this time the generator is creating pictures of someone who does exist and try to be really close to reality so that we can’t tell if it’s real or not. These uses also raise ethical questions about the possibility of using someone’s image as we see fit.
Another impressive way to use GAN is in the medical field where the researchers have made a lot of progress. In the article “Medical Image Generation Using Generative Adversarial Networks: A Review”4, the researchers explain the progress made in the medical field using image generation and the principle uses. One of them is the generation of training samples produced from original images. With GAN, the medical field can extend their image bank without having to take pictures of real patients which need their consent. Another way of using GAN is in image to image translation. In fact, there are multiple techniques for image acquisition with a lot of different imaging modalities such as “[…] ultrasonography, computed tomography (CT), positron emission tomography (PET), and magnetic resonance imaging (MRI) […]”5 and as the researchers explained the complexity and data processing is different in each case and it’s even more complex when they want to create hybrid images using two different techniques. Afterward the extraction of one modality is also complicated since an automated analysis needs high-quality images and clear features. Therefore, they are trying to develop a GAN model that would be able to translate one image modality from another.
Types of GAN
For all those examples, a different kind of GAN, so GAN with different architectures, can be used. In our study, we will focus on the conditional GAN. As explained in the paper “Conditional generative adversarial nets”6, “In an unconditioned generative model, there is no control on modes of the data being generated. However, by conditioning the model on additional information it is possible to direct the data generation process”7. These additional informations can be from any kind as class labels or data from other modalities and are here to give a direction to the generator’s task. For example, we can ask a GAN to generate pictures of cakes but if we are only interested in cheesecakes, we can add other information that will help it to generate only pictures of different kinds of cheesecakes. As a result, the generator is more specific and the discriminator is better which is making the model efficient. The conditional Gan’s architecture is the same as the original except that there is the additional informations named as label in this diagram :
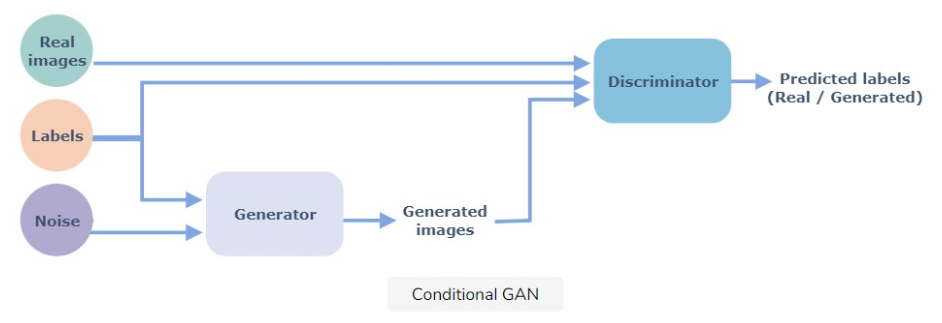 Figure 3: Model architecture of conditional GAN8
Figure 3: Model architecture of conditional GAN8
With conditional GAN it is possible to create a model such as image-super-resolution which is able to conceive the same image as in the data input but with a better quality or the text-to-image resolution, a model able to design a picture based on what the speaker describes in text as nightcafé, mid journey, etc. The one we will focus on in this study is the image-to-image translation which is usually the transformation of one picture to another with more features or different designs as they are used in the medical field to generate sample images.
References :
- CNRS - Formation FIDLE, Seq.13 “Generative Adversarial Networks (GAN)”, march 2023, https://www.youtube.com/watch?v=hvFthCbTl5c&t=2854s&ab_channel=CNRS-FormationFIDLE
- Goodfellow, I., Pouget-Abadie, J, Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2020): Generative adversarial networks. Communications of the ACM, 63(11), 139-144.
- Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017):Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1125-1134).
- Mirza, M., & Osindero, S. (2014): Conditional generative adversarial nets.
- Singh, Nripendra & Raza, Khalid. (2021): Medical Image Generation Using Generative Adversarial Networks: A Review.
-
Goodfellow, I., Pouget-Abadie, J, Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2020): Generative adversarial networks. Communications of the ACM, 63(11), 139-144. ↩
-
Tensor flow, What are GANs ?, (https://www.tensorflow.org/tutorials/generative/dcgan?hl=en) ↩
-
Overview of GAN Structure, Machine learning courses Google, (https://developers.google.com/machine-learning/gan/gan_structure?hl=en) ↩
-
Singh, Nripendra & Raza, Khalid. (2021): Medical Image Generation Using Generative Adversarial Networks: A Review. ↩
-
Singh, Nripendra & Raza, Khalid. (2021): Medical Image Generation Using Generative Adversarial Networks: A Review, page 78 ↩
-
Mirza, M., & Osindero, S. (2014): Conditional generative adversarial nets. ↩
-
Mirza, M., & Osindero, S. (2014): Conditional generative adversarial nets, page 1 ↩
-
Data scientist, Qu’est-ce qu’un Conditional GAN ?, janvier 2022, (https://datascientest.com/conditional-generative-adversarial-network-cgan) ↩